Ich habe mit einem Problem gerungen, das mich nachts wach hält: Wie kann ich leistungsstarke KI-Tools nutzen, ohne meine sensibelsten Daten an Tech-Giganten auszuliefern? Je mehr ich ChatGPT, Claude und andere Cloud-KI-Dienste nutzte, desto unbehaglicher wurde mir. Jedes Dokument, das ich hochlud, wurde auf den Servern von jemand anderem verarbeitet.

Motivation: Warum ich die Kontrolle zurückerobern musste
Dieses ganze Projekt begann aus Frustration. Ich arbeitete an vertraulichen Geschäftsdokumenten und stellte fest, dass ich keines der KI-Tools verwenden konnte, auf die ich mich verlassen hatte. Die Abhängigkeit von einem bestimmten Anbieter wurde zu einem echten Problem – jeder Anbieter hatte seine eigene API, seine eigenen Preise und seine eigenen Einschränkungen. Ich fühlte mich gefangen, und meine monatlichen KI-Rechnungen stiegen immer weiter an.
Ich begann zu überlegen: Was wäre, wenn es eine Möglichkeit gäbe, das Beste aus beiden Welten zu bekommen? Ich könnte die leistungsstarken KI-Funktionen behalten, aber alles über meine eigene Infrastruktur laufen lassen. Da entdeckte ich LibreChat und beschloss, etwas zu entwickeln, das mir die volle Kontrolle geben würde – und eine Vorlage zu schaffen, der andere Unternehmen mit ähnlichen Herausforderungen folgen könnten.
Was ich gebaut habe: Eine Blaupause für private KI
Das Private-AI Projekt wurde meine Antwort auf dieses Dilemma. Ich habe ein selbstgehostetes LibreChat-Setup auf AWS eingerichtet, das mir Zugriff auf mehrere KI-Modelle bietet und gleichzeitig die Daten unter meiner Kontrolle hält. LibreChat ist ein ziemlich cooles Open-Source-Projekt, eine Chat-Plattform im Stil von ChatGPT mit einer ausgereiften, professionellen Basis, die vollen Datenschutz und umfassende Konfigurierbarkeit ermöglicht.
Was als persönliche Lösung begann, wurde schnell zu etwas Größerem – ein reproduzierbarer Entwurf für jedes Unternehmen, das mit den gleichen Kompromissen zwischen Datenschutz und Leistungsfähigkeit zu kämpfen hat.
Das ist mein Ergebnis: LibreChat, ein innovatives Open-Source-Projekt, das eine Webschnittstelle bietet, die mit ChatGPT konkurriert, aber auf einem eigenen Server läuft. Mit dieser konkurrenzfähigen Alternative kann man nahtlos zwischen lokalen Modellen, Cloud-Modellen von AWS Bedrock und öffentlichen KI-Anbietern wie Antrophic oder OpenAi wechseln. Wenn man mit sensiblen Dokumenten arbeiten, bleibt alles lokal. Wenn man die Leistung von Claude oder GPT-4 benötigt, kann man auch diese nutzen.
Die Einrichtung umfasst eine Dokumentenverarbeitung, bei der man PDFs hochladen und mit ihnen chatten können, ohne dass die Dateien jemals den eingenen Server verlassen. Alles läuft in Docker-Containern mit entsprechender Benutzerverwaltung – perfekt für Teams, die zusammenarbeiten und gleichzeitig die Datenhoheit behalten müssen.
Die Schnittstelle: Wie es tatsächlich aussieht
LibreChat bietet mir eine saubere, vertraute Oberfläche, die sich genauso anfühlt wie die von ChatGPT oder Claude. Ich kann verschiedene KI-Modelle aus einer Dropdown-Liste auswählen, benutzerdefinierte Agenten mit spezifischen Persönlichkeiten erstellen und alle meine Unterhaltungen an einem Ort verwalten.
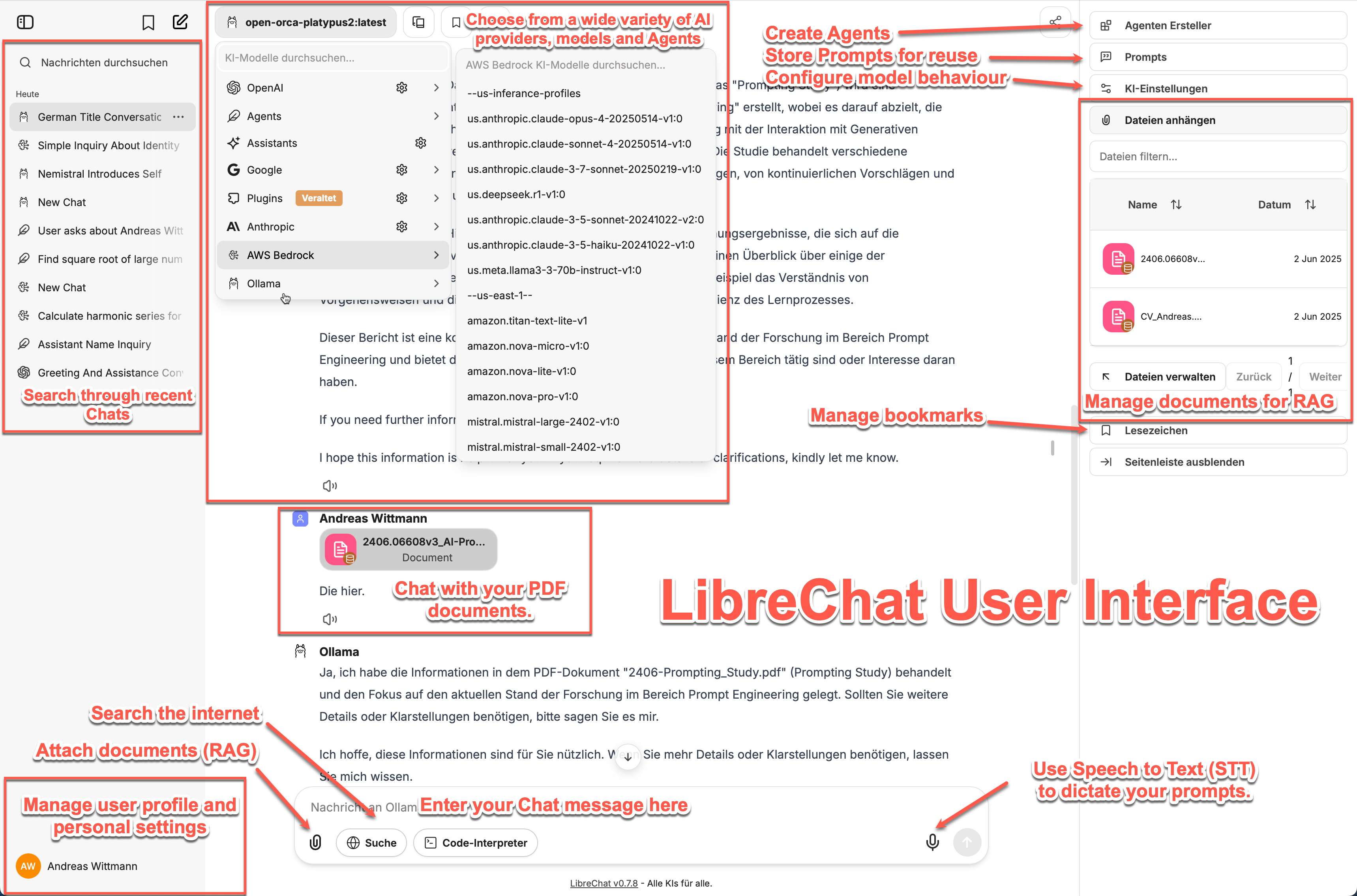
Was ich am meisten liebe, ist die Flexibilität. Morgens verwende ich vielleicht ein lokales Ollama-Modell für das Brainstorming (wobei alles privat bleibt), dann wechsle ich zu Claude für komplexe Analysen und dann wieder zu einem lokalen Modell für die Dokumentenverarbeitung. Die Schnittstelle macht das nahtlos.
Die Funktion zum Hochladen von Dokumenten war für mich ein großer Fortschritt. Ich kann PDFs per Drag & Drop hochladen, und das System erstellt die Einbettungen lokal auf meinem Server. Dann kann ich Fragen zum Inhalt stellen, ohne dass das Dokument jemals mit externen Servern in Berührung kommt. Das war genau das, was ich für die Arbeit mit vertraulichen Materialien brauchte.
Die technische Einrichtung: Einfacher, als man denkt
Ich habe dieses Projekt auf AWS mit einer ziemlich einfachen Architektur aufgebaut. Alles läuft in Docker-Containern auf einer einzigen EC2-Instanz, was die Verwaltung viel einfacher macht, als ich anfangs dachte.
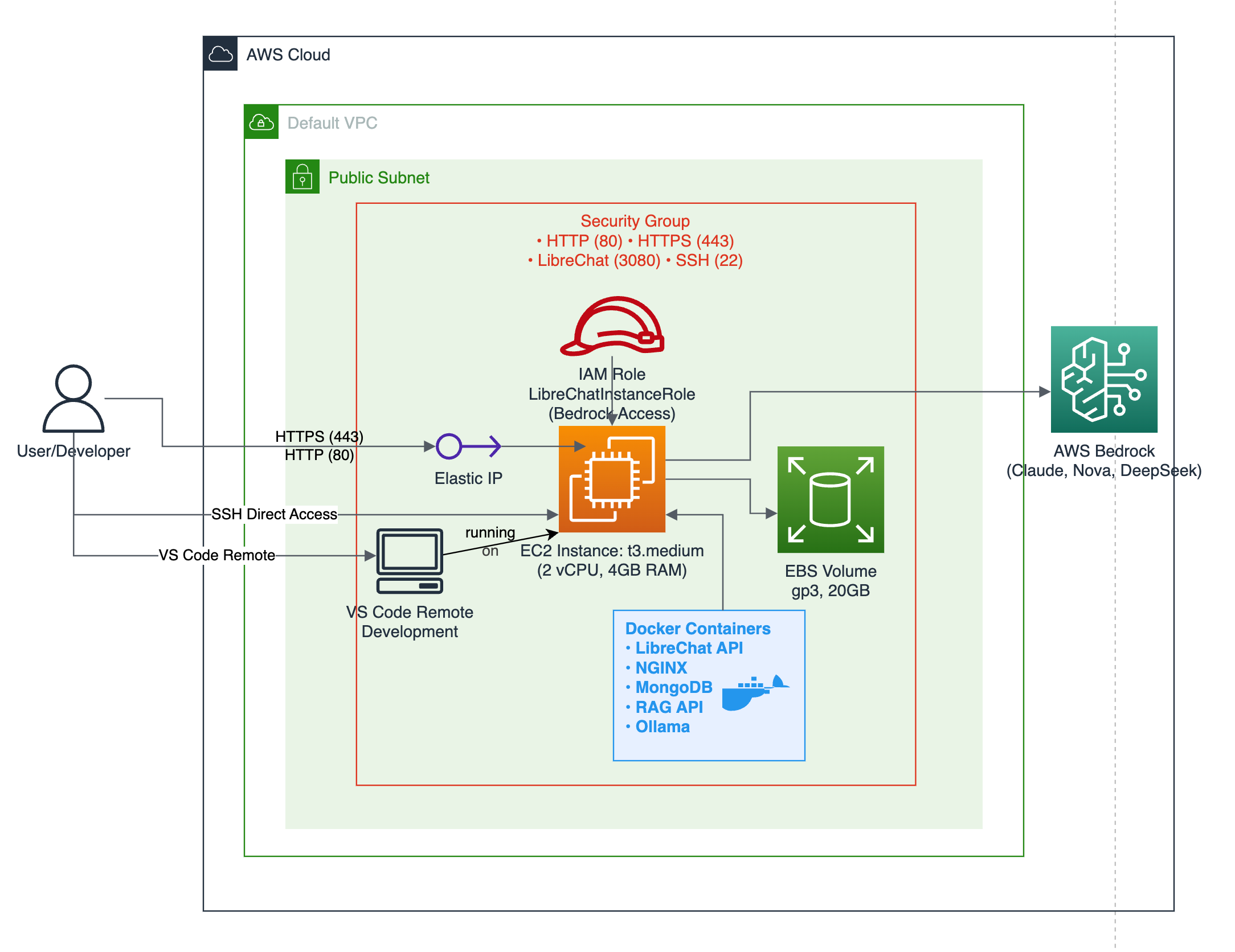
Die AWS-Einrichtung ist sauber – eine EC2-Instanz mit den richtigen Sicherheitsgruppen, eine elastische IP, damit sich die Adresse nicht ändert, und IAM-Rollen, die den Server mit AWS Bedrock-Modellen kommunizieren lassen. Anfangs habe ich viel zu viel Zeit damit verbracht, die Vernetzung zu kompliziert zu gestalten, aber der einfache Ansatz hat am besten funktioniert.
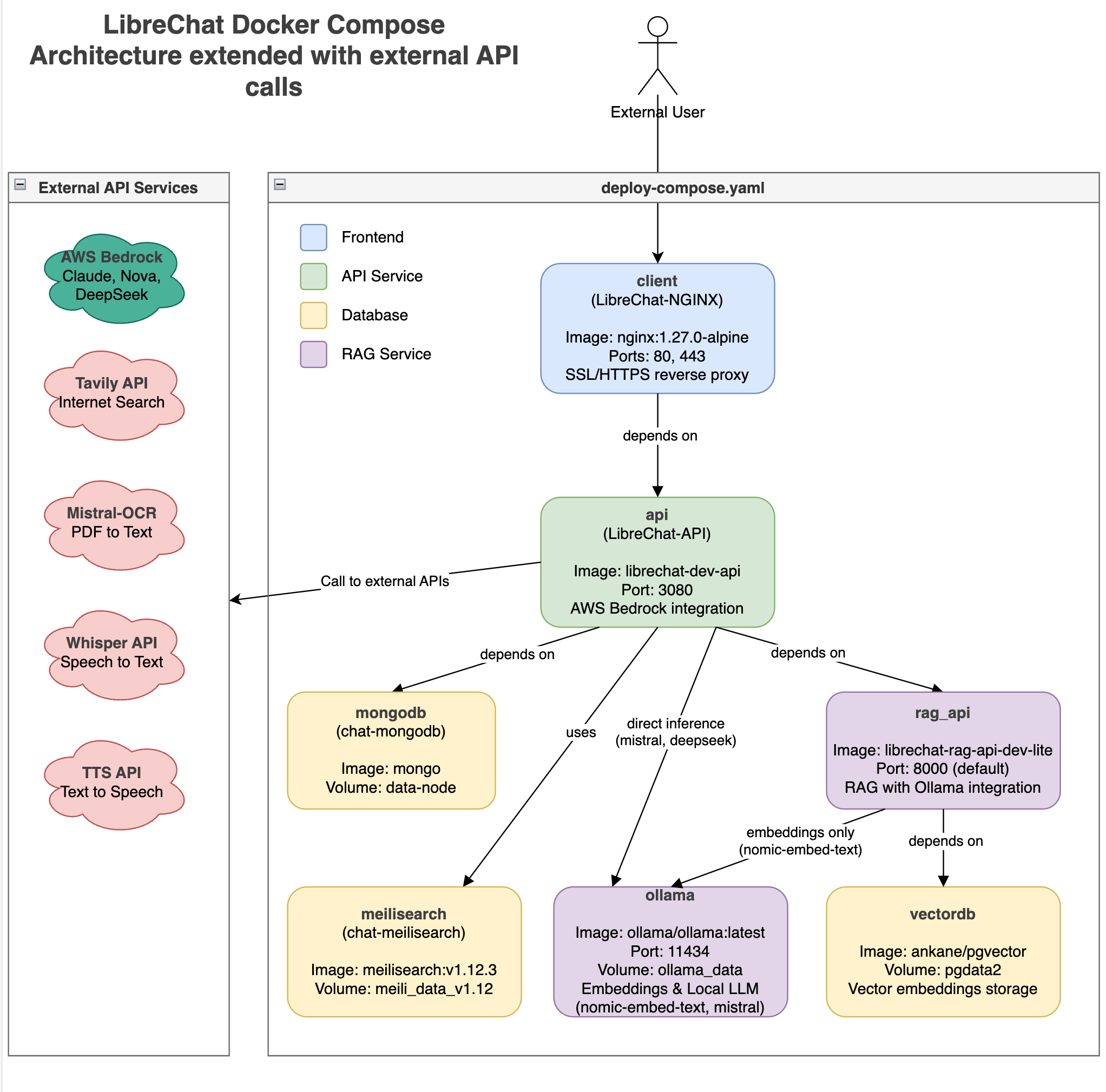
Auf dem Docker-Setup läuft LibreChat als Hauptanwendung, MongoDB zum Speichern von Konversationen und nginx als Reverse-Proxy mit SSL. Wenn ich lokale KI-Modelle verwenden möchte, füge ich Ollama-Container hinzu, die die GPU nutzen können. Alles kommuniziert miteinander über Docker-Netzwerke, was für Sicherheit und Ordnung sorgt.
Aufstocken: Aus meinen Fehlern lernen
Eine meiner wichtigsten Lektionen war die Dimensionierung der Server. Ich begann mit einer winzigen t3.medium-Instanz und dachte, das würde reichen. Falsch gedacht. Sobald ich versuchte, lokale KI-Modelle auszuführen, kam alles zum Stillstand.
| Instanztyp | vCPUs | Speicher | GPU | Wofür ich es benutzte |
|---|---|---|---|---|
| t3.medium | 2 | 4 GB | Keine | Einfache Tests, nur Cloud-Modelle |
| g4dn.xlarge | 4 | 16 GB | NVIDIA T4 (16 GB) | Lokale Modelle, Dokumentenverarbeitung |
| g6.12xlarge | 48 | 192 GB | 4x NVIDIA L4 (96 GB insgesamt) | Hohe Arbeitslast, mehrere Benutzer |
Die „t3.medium“ war für die Weboberfläche und die Verwendung von Cloud-Modellen gut geeignet, aber vergessen Sie alles, was lokal ausgeführt wird. Als ich auf g4dn.xlarge mit einer GPU aufrüstete, konnte ich plötzlich kleine Sprachmodelle ausführen und Dokumente lokal verarbeiten. Das war ein Unterschied wie Tag und Nacht.
Für die letzte Testphase habe ich mir eine Instanz von „g6.12xlarge“ zugelegt. Dieses Ungetüm konnte mehrere große Modelle gleichzeitig verarbeiten und fühlte sich an wie eine richtige KI-Workstation in der Cloud. Die Kosten haben mich zu Tränen gerührt, aber für ernsthafte Arbeit ist es das wert.
Mein Rat: Fangen Sie klein an, um alles zu testen, und erhöhen Sie dann die Größe, je nachdem, was Sie tatsächlich brauchen. Das Schöne an diesem Ansatz ist, dass das Upgrade nur ein paar Terraform-Befehle erfordert.
Der Umstieg auf die g6.12xlarge war wie der Wechsel von einem Fahrrad zu einem Ferrari. Vier NVIDIA L4-GPUs mit 96 GB Videospeicher bedeuteten, dass ich mehrere große Modelle gleichzeitig ausführen konnte, ohne ins Schwitzen zu kommen. Plötzlich konnte ich Modelle in der Größe von Claude lokal laufen lassen und gleichzeitig mehrere Benutzer bedienen.
Was die Leistung angeht, habe ich Folgendes gelernt: Die kleine t3.medium eignet sich hervorragend zum Testen der Weboberfläche und zum Ausprobieren von Cloud-Modellen, aber denken Sie nicht einmal an lokale KI. Das g4dn.xlarge ist der ideale Ort für den Einstieg in lokale Modelle – ich konnte 7B-Parameter-Modelle ziemlich reibungslos ausführen. Aber wenn Sie die wirklich großen Modelle (13B+) mit anständiger Geschwindigkeit ausführen wollen, brauchen Sie etwas wie das g6.12xlarge.
Live-Skripting: Eine Dokumentation, die wirklich funktioniert
Hier ist etwas, das mich wirklich begeistert – die Art und Weise, wie ich dieses gesamte Projekt dokumentiert habe. Ich habe das so genannte Live-Scripting verwendet, einen dokumentationsorientierten Arbeitsstil, den ich vor Jahren erfunden und in vielen Kundenprojekten eingesetzt habe. Dabei wird ein Dokument erstellt, in dem jeder einzelne Befehl direkt ausgeführt werden kann. Keine Tutorials mehr, nur um dann festzustellen, dass Schritt 3 nicht mehr funktioniert.
Ich habe alles in Emacs-Org-Mode geschrieben, wodurch ich ausführbare Codeblöcke direkt in die Dokumentation einbetten kann. Wenn ich das Projekt durcharbeite, kann ich buchstäblich jeden Befehl durch Drücken von F4 ausführen. Aber auch wenn jemand nicht mit Emacs arbeitet, kann er jeden Befehl kopieren und einfügen und er wird genau so funktionieren, wie er geschrieben wurde.
Dieser Ansatz hat mir unzählige Stunden der Fehlersuche in veralteten Anweisungen erspart. Herkömmliche Dokumentation ist schnell veraltet – APIs ändern sich, Softwareversionen werden aktualisiert, und plötzlich funktioniert nichts mehr. Mit Live-Scripting bleibt meine Dokumentation auf dem neuesten Stand, denn ich teste sie jedes Mal, wenn ich sie verwende.
Die gesamte Implementierung ist in sieben klare Phasen unterteilt, von der Einrichtung der grundlegenden Infrastruktur bis zum Hinzufügen fortgeschrittener KI-Funktionen. Zu jedem Schritt gehören sowohl die auszuführenden Befehle als auch Erklärungen, was passiert und warum. Es ist, als würde mich ein sachkundiger Kollege durch den Prozess führen.
Fazit: Endlich KI nach meinen Vorstellungen
Die Entwicklung dieses privaten KI-Assistenten löste nicht nur mein unmittelbares Problem, sondern wurde zu etwas Größerem – zu einer bewährten Blaupause, der jedes Unternehmen folgen kann. Was als persönliche Frustration begann, wurde zu einer reproduzierbaren Implementierungsstrategie für Unternehmen, die mit dem gleichen Dilemma zwischen Privatsphäre und Leistungsfähigkeit konfrontiert sind.
Und das Beste daran? Die Unternehmen müssen sich nicht mehr entscheiden. Sensible Arbeiten bleiben auf lokalen Modellen, komplexe Analysen können bei Bedarf weiterhin auf Cloud-KI zurückgreifen – aber es ist Ihre Infrastruktur, Ihre Entscheidung, Ihre Kontrolle.
Die Live-Skripting-Dokumentation macht es sehr einfache, diese Blaupause zu teilen. Jeder Befehl funktioniert genau so, wie er geschrieben wurde, was bedeutet, dass andere Teams diese Lösung ohne die üblichen Bereitstellungsprobleme einsetzen können.
Für Unternehmen, die leistungsstarke KI wünschen, ohne die Datenhoheit aufzugeben, ist dieser Ansatz genau richtig. Die Technologie ist endlich an einem Punkt angelangt, an dem eine eigene KI nicht nur für Tech-Giganten möglich ist, sondern für jedes Unternehmen, das bereit ist, in die Unabhängigkeit seiner Daten zu investieren.
Ressourcen und Links
Projektdokumentation
- Complete Deployment Guide (PDF) – Die vollständige Live-Skript-Dokumentation mit allen Befehlen und Erklärungen, die benötigt werden, um dieses Setup von Grund auf einzurichten. Jeder Befehl ist getestet und ausführbar.
GitHub-Repositories
- Privates KI-Projekt – Meine komplette Implementierung einschließlich Terraform-Konfigurationen, Docker-Setup und dem gesamten Infrastruktur-Code, der in diesem Einsatz verwendet wird.
- LibreChat Official Repository – Das innovative Open-Source-Projekt, das dies alles möglich macht. Eine leistungsstarke, ChatGPT-ähnliche Anwendung, die Sie auf Ihrer eigenen Infrastruktur mit Unterstützung für mehrere KI-Anbieter ausführen können.