📄 Download: PDF-Version dieses Dokuments.
Achtsamkeit für Teams: Programme, die Fokus in den Arbeitsalltag bringen.

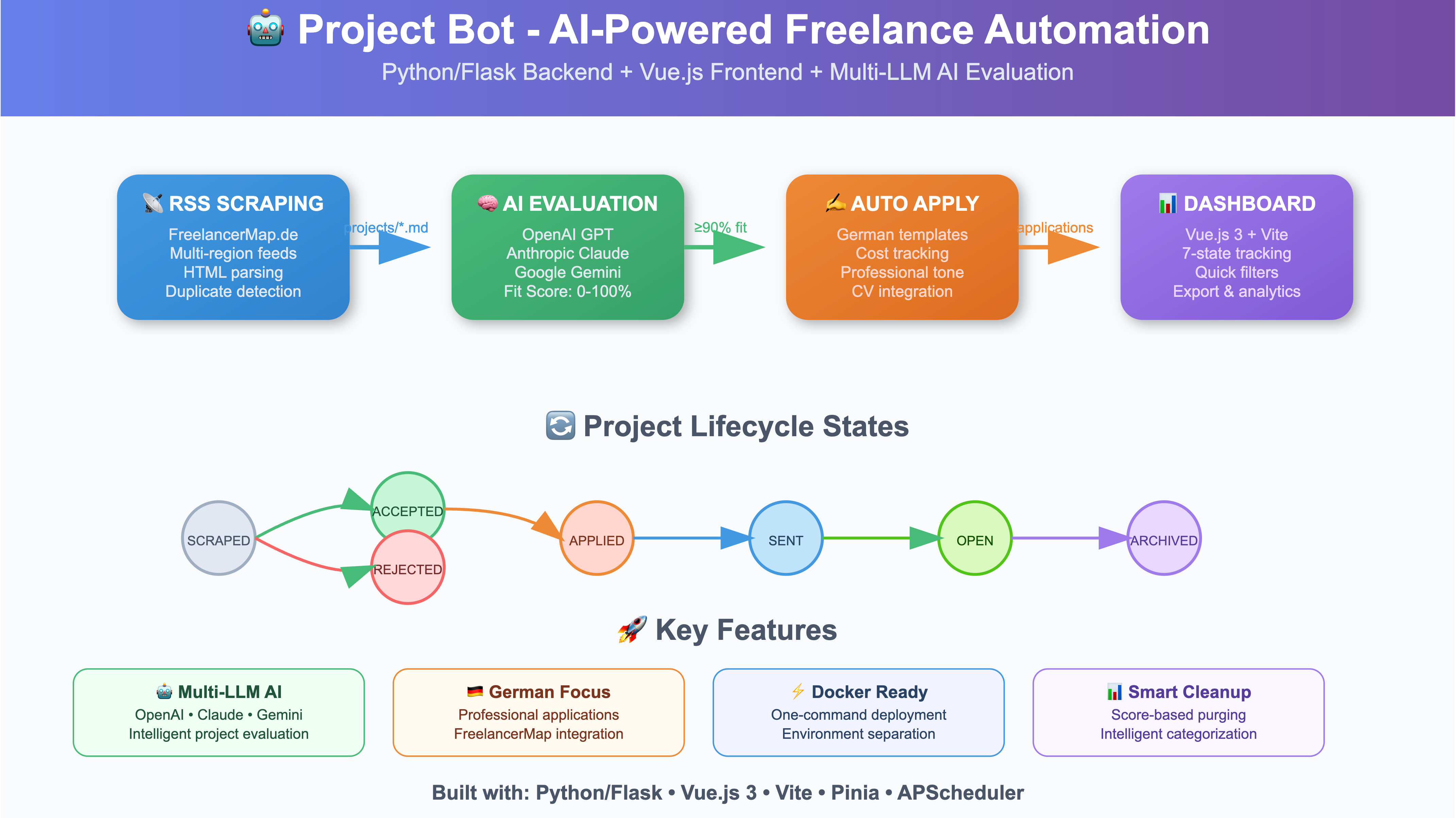
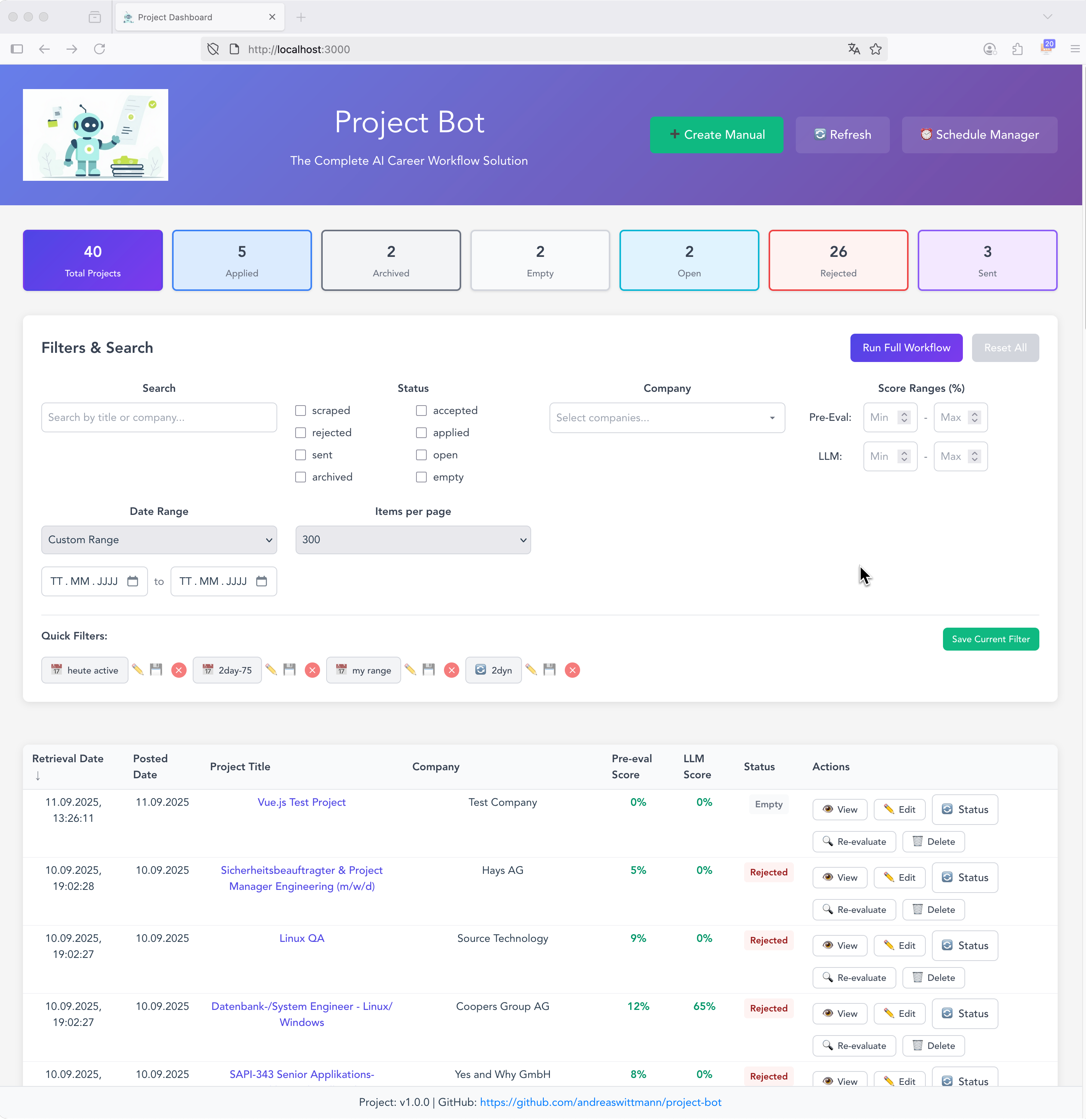
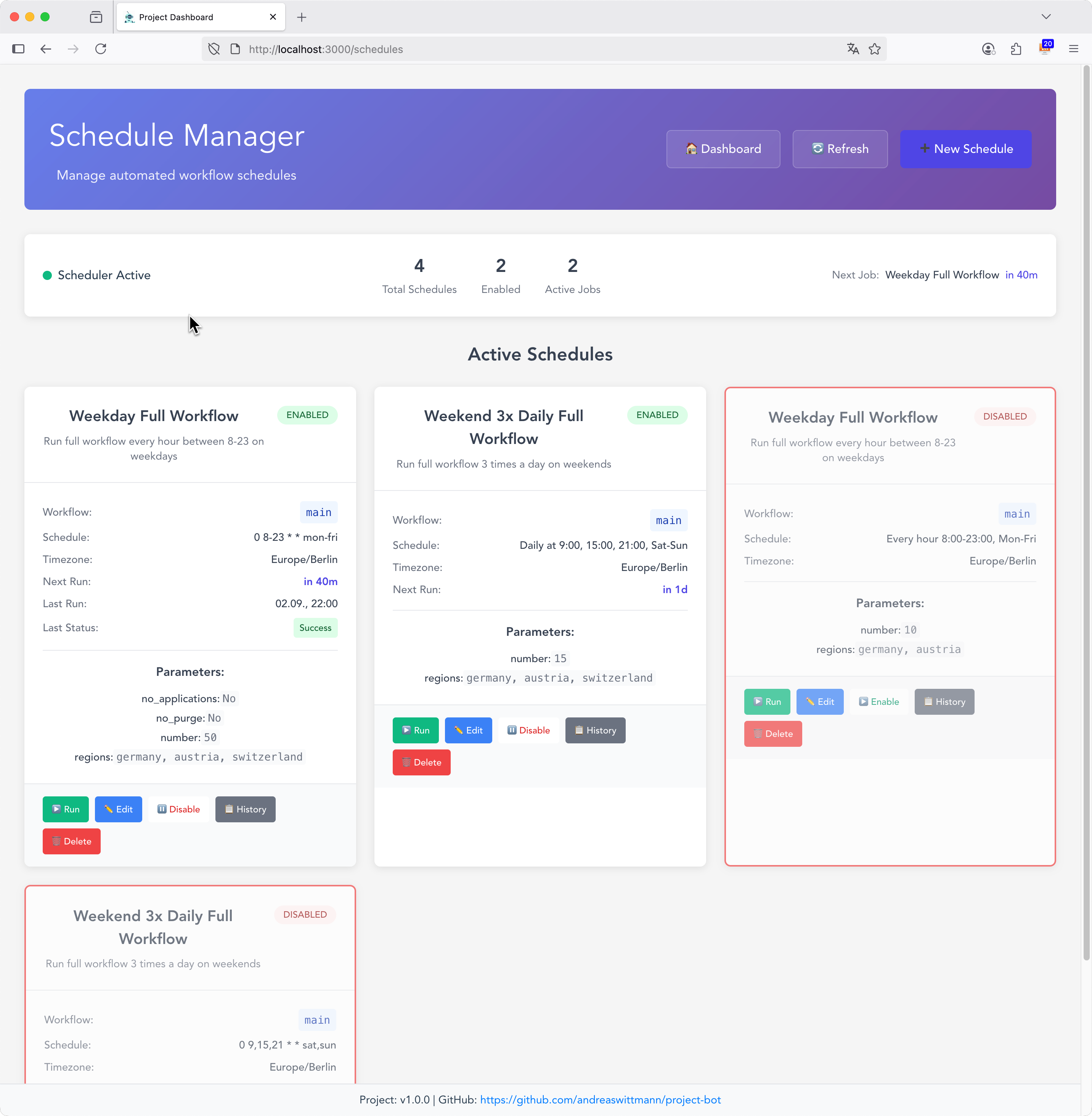
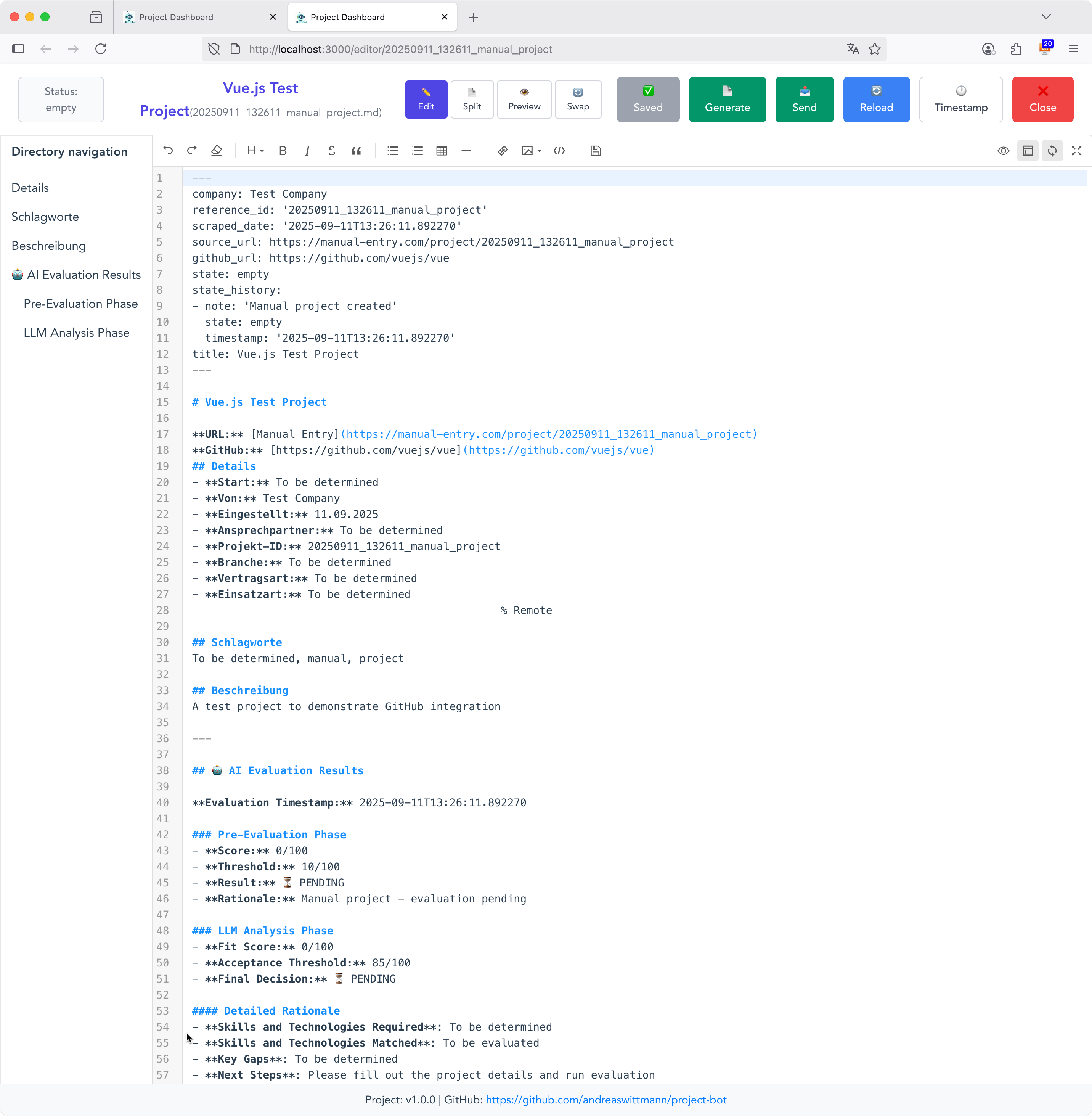
1. Zwei Programme, ein Ziel
Seit diesem Jahr bin ich zertifizierter Momentum-Trainer, was meine CEB-Ausbildung von 2017 ergänzt. Der Grund für ein zweites Programm ist einfach: 42 Stunden CEB sind für manche Unternehmen schlicht zu viel. Momentum hingegen ist kompakter, evidenzbasiert und fügt sich leichter in den Arbeitsalltag ein.
Beide Programme vermitteln Achtsamkeit und emotionale Kompetenz, aber auf unterschiedliche Weise. Ich halte das für eine sinnvolle Erweiterung – nicht weil CEB nicht funktioniert, sondern weil verschiedene Kontexte verschiedene Formate brauchen.
2. Gerade jetzt, nicht trotzdem
Überall werden Entwicklungsbudgets gekürzt, was angesichts des wirtschaftlichen Drucks verständlich ist. Bei Achtsamkeitsprogrammen halte ich diese Kürzungen dennoch für einen Fehler.
Wenn Unsicherheit herrscht, steigt der Stress. Mitarbeitende sorgen sich um ihre Zukunft, treffen schlechtere Entscheidungen und kommunizieren gereizter – das Team leidet, die Arbeit leidet. Genau dann braucht es Werkzeuge, um mit Druck umzugehen.
Meine Erfahrung zeigt: Achtsamkeit ist keine Wellness-Maßnahme, sondern stabilisiert Teams unter Druck. Ein Burnout oder ein gescheitertes Projekt kostet letztlich mehr als jedes Training.
3. Mein Weg
Ich bin seit fast 30 Jahren IT-Berater und kenne den Druck komplexer Projekte aus der täglichen Arbeit in Architektur, Cloud und Projektleitung. Parallel dazu meditiere ich seit 2006 täglich.
Der Anfang reicht weiter zurück: In den 90ern lernte ich bei Helmut Vogler in Berlin Ki no Kenkyukai Aikido mit seinen Atem- und Meditationsübungen kennen. Der eigentliche Durchbruch kam jedoch nach einem Sabbatical in Südamerika, als ich einem inneren Impuls folgte und dabei blieb.
In den Jahren danach studierte ich bei Alan Wallace und Tsoknyi Rinpoche, bevor ich 2017 die CEB-Trainerausbildung abschloss. Seitdem biete ich Achtsamkeitstraining an, besonders für IT-Teams. Was mich dabei interessiert, ist die Verbindung von östlicher Praxis mit westlichem Arbeitsalltag – gerade in der Technologiebranche sehe ich, wie wertvoll innere Klarheit sein kann.
4. Warum Momentum?
CEB geht tief: Paul Ekmans Emotionsforschung kombiniert mit Meditationen von Alan Wallace ergibt 42 Stunden intensiver Arbeit an emotionalem Bewusstsein und Regulation.
Momentum ist anders konzipiert. Das Programm erstreckt sich über sechs Wochen mit kürzeren Einheiten und ist für Online- wie Präsenzformate optimiert. Es integriert Neurowissenschaft, positive Psychologie und Organisationspsychologie, unterstützt durch eine App und ein Buddy-System.
Für den Einstieg in Achtsamkeit im Unternehmen halte ich Momentum für besser geeignet, während CEB für tiefere emotionale Arbeit meine erste Wahl bleibt.
5. Klarer Kopf, wenn alles brennt
Stellen Sie sich ein IT-Team vor, das unter Deadline-Druck steht – Umstrukturierung, zwei Kündigungen. In einer Pause fragt jemand: „Warum reden wir über Atmung, wenn uns das Projekt um die Ohren fliegt?“
Die Frage ist berechtigt. Meine Antwort wäre: „Genau deshalb. Wenn alles brennt, brauchen Sie einen klaren Kopf.“
Solche Einwände kenne ich aus meiner Arbeit. Niemand ändert nach einem Workshop seine Meinung komplett. Aber wer eine konkrete Technik mitnimmt und sie nutzt, hat etwas gewonnen. Das ist realistisch: Achtsamkeit ist kein Wundermittel, sondern Übung.
6. Meine ersten Einsichten
Als ich 2017 mit CEB begann, dachte ich, gute Inhalte würden für sich sprechen. Das war naiv.
Unternehmen brauchen Anschlussfähigkeit: 45-Minuten-Slots, messbare Ergebnisse, keine Esoterik. Momentum erfüllt diese Anforderungen besser als CEB, weshalb ich froh bin, heute beide Werkzeuge anbieten zu können.
7. Zum Mitnehmen
- Achtsamkeit stabilisiert – gerade unter Druck, nicht trotzdem.
- Format muss passen – Momentum für den Einstieg, CEB für Tiefenarbeit.
- Qualifikation zählt – achten Sie auf eigene Praxis, nicht nur Zertifikate.
- IT ist mein Kontext – ich verstehe die spezifischen Herausforderungen.
- Übung braucht Zeit – ein Workshop ist ein Anfang, kein Ergebnis.
Seit Mitte des Jahres 2025 bin ich als Momentum-Trainer gelistet. Sprechen Sie mich an – gemeinsam finden wir das passende Format für Ihr Team.
8. Weitere Informationen
- Cultivating Emotional Balance (CEB): cultivating-emotional-balance.org
- Mein CEB-Angebot: anwi.gmbh/?page_id=368
- Momentum Programm: momentum-mindfulness.de
- Mein Momentum-Profil: momentum-mindfulness.de/andreas-wittmann
9. Über den Autor
Andreas Wittmann ist IT-Berater und Achtsamkeitstrainer aus Hamburg. Meditationspraxis seit 2006, CEB-Trainer seit 2017, Momentum-Trainer seit 2025.
Kontakt: | https://anwi.gmbh